写在前面
本文来由: 实习期间,看到同事在手动采集数据,近百个港口,大量的复制粘贴,体力劳动,被我无情的嘲讽了一番,然后答应帮他写个爬虫,减少体力消耗,争取多活两年,所以,才有今天这篇博文。
本项目结构
- spider
- pic: 用于生成readme的图片;
- readme: 帮助理解整个项目结构以及代码生成的流程;
- result: 生成的结果存放在这里;
- source: 代码和港口映射表在这里,港口映射表需要补充,代码里面的token在每次使用之前需要更新;
爬虫探索流程
本文目标是从坤州获取对应港口的运价信息;
以 NINGBO -> HAMBURG 为例解决单个港口爬取问题
获取报价页面
首先,查询页面输入 NINGBO -> HAMBURG,点击查询,可以获取该request的详细信息:
request headers:
GET /portal/fclratequery/form/index/?pol=CNNGB&fd=DEHAM&loadingtype=FCL HTTP/1.1
Host: portal.kun-logistics.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://portal.kun-logistics.com/portal/form/home/index/
Accept-Encoding: gzip, deflate, sdch, br
Accept-Language: zh-CN,zh;q=0.8
Cookie: ASP.NET_SessionId=qlxcrlplrvfgkc24p2mn500z; uid=6ad87ee9-13b0-4d18-906a-d0a7dcae1322
其实以 url: https://portal.kun-logistics.com/portal/fclratequery/form/index/?pol=CNNGB&fd=DEHAM&loadingtype=FCL 进行请求就可以获得该报价页面,但是问题在于报价分为多页,该request只返回首页数据,其余页以ajax的形式存在,需要再次请求,所以继续捕获点击下一页时的request对比两者的区别;
翻页数据request分析
page2 request headers:
POST https://portal.kun-logistics.com/portal/fclratequery/form/ajax HTTP/1.1
Host: portal.kun-logistics.com
Connection: keep-alive
Content-Length: 194
Accept: */*
Origin: https://portal.kun-logistics.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Content-Type: application/json; charset=UTF-8
Referer: https://portal.kun-logistics.com/portal/fclratequery/form/index/?pol=CNNGB&fd=DEHAM&loadingtype=FCL
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.8
Cookie: ASP.NET_SessionId=qlxcrlplrvfgkc24p2mn500z; uid=6ad87ee9-13b0-4d18-906a-d0a7dcae1322
{"key":"getlist","data":"{\"carrierid\":\"\",\"sailingdate\":\"\",\"portofloadingcode\":\"CNNGB\",\"finaldestinationcode\":\"DEHAM\",\"loadingtype\":\"FCL\",\"page\":\"2\"}","xc_token":"xTMMxL"}
page3 request headers:
POST https://portal.kun-logistics.com/portal/fclratequery/form/ajax HTTP/1.1
Host: portal.kun-logistics.com
Connection: keep-alive
Content-Length: 194
Accept: */*
Origin: https://portal.kun-logistics.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Content-Type: application/json; charset=UTF-8
Referer: https://portal.kun-logistics.com/portal/fclratequery/form/index/?pol=CNNGB&fd=DEHAM&loadingtype=FCL
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.8
Cookie: ASP.NET_SessionId=qlxcrlplrvfgkc24p2mn500z; uid=6ad87ee9-13b0-4d18-906a-d0a7dcae1322
{"key":"getlist","data":"{\"carrierid\":\"\",\"sailingdate\":\"\",\"portofloadingcode\":\"CNNGB\",\"finaldestinationcode\":\"DEHAM\",\"loadingtype\":\"FCL\",\"page\":\"3\"}","xc_token":"xTMMxL"}
page4 request headers:
POST https://portal.kun-logistics.com/portal/fclratequery/form/ajax HTTP/1.1
Host: portal.kun-logistics.com
Connection: keep-alive
Content-Length: 194
Accept: */*
Origin: https://portal.kun-logistics.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Content-Type: application/json; charset=UTF-8
Referer: https://portal.kun-logistics.com/portal/fclratequery/form/index/?pol=CNNGB&fd=DEHAM&loadingtype=FCL
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.8
Cookie: ASP.NET_SessionId=qlxcrlplrvfgkc24p2mn500z; uid=6ad87ee9-13b0-4d18-906a-d0a7dcae1322
{"key":"getlist","data":"{\"carrierid\":\"\",\"sailingdate\":\"\",\"portofloadingcode\":\"CNNGB\",\"finaldestinationcode\":\"DEHAM\",\"loadingtype\":\"FCL\",\"page\":\"4\"}","xc_token":"xTMMxL"}
现在清晰了,下一页和首页的headers区别如下:
- 下一页是 post 类型, 首页是 get ;
- 请求的url不同, 下一页直接对Ajax发起请求;
- 下一页包括了一串 padload 信息,用以指定始发港、目的港、船公司、页数、xc_token等信息;
这个时候思路也明了了,主要流程如下:
1. 确定始发港、目的港以及目的港港口类型;
2. 组成要访问的首页url,获取首页页面,解析出一共有几页;
3. 修改各个页面的url和padload信息,分别发起请求,获取页面信息,并进行解析;
4. 将各个子页面的报价信息整合到一起即可;
代码实现
import pandas as pd
import requests
import json
from bs4 import BeautifulSoup
def get_page_cnt(SITE_URL):
"""get total pages' cnt"""
try:
first_response = requests.get(url=SITE_URL)
except ConnectionError as e:
first_response = requests.get(url=SITE_URL)
first_page = first_response.content.decode('utf-8')
soup = BeautifulSoup(first_page, "lxml")
PAGE_CNT = soup.find_all('span', class_=None)[1].get_text().split()[-2]
return int(PAGE_CNT)
def parse_page(soup):
"""parse page to DataFrame."""
page_return = soup.find_all('tr', class_="tr-bd")
page_result = list()
for item in page_return:
result = dict()
result['pol'] = item.find('div', class_='pol').get_text()
result['pod'] = item.find('div', class_='fd').get_text()
result['carrier'] = item.find(
'div', class_='t-muted carrier').get_text()
result['schedule'] = item.find('div', class_='sailingsche').get_text()
result['pot'] = item.find_all('td')[2].find_all('div')[0].get_text()
result['date'] = item.find('div', class_='tt').get_text(strip=True)
for i in item.find_all('td', class_='td-price'):
result[i.find('h5').get_text()] = i.find('div').get_text()
result['start_date'] = item.find_all('td', class_=None)[-2].get_text()
result['end_date'] = item.find_all('td', class_=None)[-1].get_text()
page_result.append(result)
return pd.DataFrame(page_result)
def update_headers_pageCnt(POD, POD_TYPE):
"""get headers and page counts for this port.
Params:
POD: standlized code for pod;
POD_TYPE: ports' type like 'FCL';
Return:
headers: request headers;
page_cnt: prices' amount for this port;
"""
SITE_URL = "https://portal.kun-logistics.com/portal/fclratequery/form/index/?pol=CNNGB&fd=" + \
POD + "&loadingtype=" + POD_TYPE
headers = {
"Cookie": "ASP.NET_SessionId=qlxcrlplrvfgkc24p2mn500z; uid=6ad87ee9-13b0-4d18-906a-d0a7dcae1322",
"Content-Type": "application/json; charset=UTF-8",
"Host": "portal.kun-logistics.com",
"Referer": SITE_URL,
"Accept": "*/*",
"X-Requested-With": "XMLHttpRequest",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8"
}
PAGE_CNT = get_page_cnt(SITE_URL)
return headers, PAGE_CNT
def update_payload(Payload_page, POD, POD_TYPE):
"""update the page number u want to crawl.
Params:
Paload_page: int, page number;
Return:
Payload: payload dict.
"""
Payload_data = "{\"carrierid\":\"\",\"sailingdate\":\"\",\"portofloadingcode\":\"CNNGB\",\"finaldestinationcode\":\"" + \
POD + "\",\"loadingtype\":\"" + POD_TYPE + \
"\",\"page\":\"" + str(Payload_page) + "\"}"
Payload = {
"key": "getlist",
"data": Payload_data,
"xc_token": Payload_xc_token
}
return Payload
def get_pod_result(POD, POD_TYPE):
headers, PAGE_CNT = update_headers_pageCnt(POD=POD, POD_TYPE=POD_TYPE)
FNL_DF = pd.DataFrame()
for Payload_page in range(1, PAGE_CNT + 1):
Payload = update_payload(Payload_page, POD=POD, POD_TYPE=POD_TYPE)
reponse = requests.post(
url=PAGE_URL, data=json.dumps(Payload), headers=headers)
one_page = reponse.content.decode('utf-8')
soup = BeautifulSoup(one_page, "lxml")
page_df = parse_page(soup)
FNL_DF = FNL_DF.append(page_df)
return FNL_DF.reset_index(drop=True)
if __name__ == '__main__':
PAGE_URL = "https://portal.kun-logistics.com/portal/fclratequery/form/ajax"
PORT_PATH = 'POD.xlsx'
OUTPUT_PATH = 'OUTPUT.xlsx'
Payload_xc_token = "ztMp8r"
pod_data = pd.read_excel(PORT_PATH).dropna()
print("【INFO】searching for {0} ports' prices".format(pod_data.shape[0]))
ALL_PRICE = pd.DataFrame()
for pod, pod_type in zip(pod_data['CODE'], pod_data['TYPE']):
pod_result = get_pod_result(POD=pod, POD_TYPE=pod_type)
print("【RESULT】{0} have {1} records!".format(pod, pod_result.shape[0]))
ALL_PRICE = ALL_PRICE.append(pod_result)
if ALL_PRICE.shape[0]:
print("【FINALLY】total records: {0}".format(ALL_PRICE.shape[0]))
ALL_PRICE.to_excel(OUTPUT_PATH)
else:
print("【WARN】TRY ANOTHER TOKEN PLEASE!")
代码运行须知
- Payload_xc_token 是一个动态的变量,
需要看官自己去随便查询一个港口的信息,如HAMBURG,使用chrome打开,然后点击F12,开启调试流程:
- 点击 network;
- 点击 下一页;
- 左侧 name 当中,出现 ajax, 双击;
- 点击右侧的 headers, 在headers中 找到 request payload , 其中 xc_token 的值 就是我们需要的 Payload_xc_token , 复制过来即可;

- 港口标准代码获取
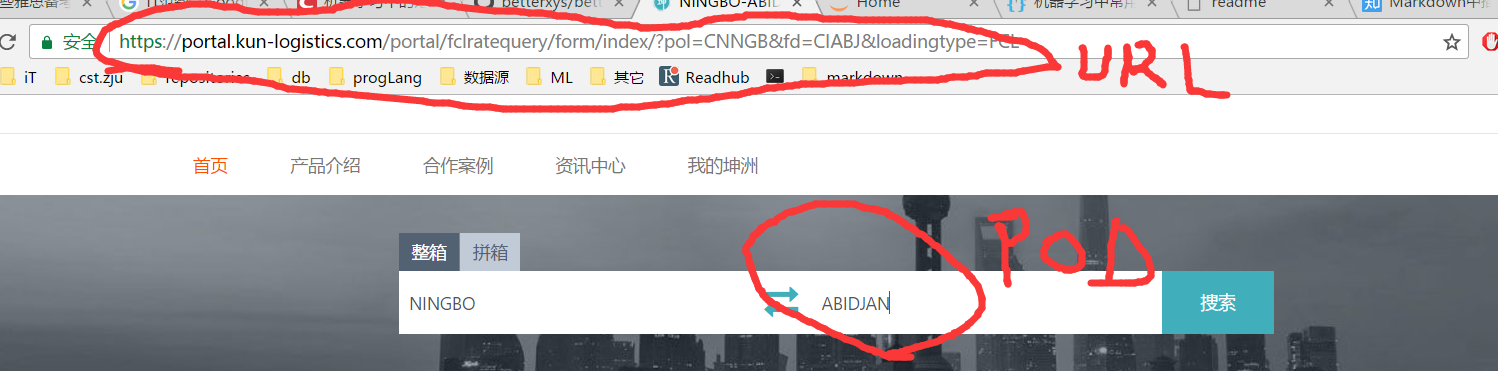
自行获取,更新到 EXCEL 当中, 获取方式如下:- 进入坤州物流首页;
- 在搜索框输入 始发港 和 目的港, 点击 搜索;
-
chrome 地址栏的url当中包含有我们需要的信息:
URL = https://portal.kun-logistics.com/portal/fclratequery/form/index/?pol=CNNGB&fd=CIABJ&loadingtype=FCL
pol=CNNGB
fd=CIABJ (这是目的港)
loadingtype=FCL (不知道是什么,可能是港口类型?)
- 我们需要的是 fd 和 loadingtype, 将其更新到 pod.xlsx 的对应位置即可;